When I first started using Kotlin's coroutines for the first time, I was admittedly a bit baffled. It's not that I was unfamiliar with parallel programming. Rather, it seemed as though every language had a different way of doing things, and that Kotlin's version of concurrency was comparatively distinct.
Having bounced from Java runnables to Javascript callbacks to promises/futures to async/await, seeing new words in Kotlin like launch, suspend, and scope led to questions:
- What is a coroutine and how is it different from a thread?
- What is "scope" and why is it important?
- What happens if something goes wrong in a coroutine?
What are Coroutines?
Permalink to "What are Coroutines?"To start, it's helpful to reference what the Kotlin docs utilize as their hello-world example of coroutines:
launch {
delay(1000L)
println("World!")
}
The launch here starts a coroutine which prints "World!" after one second. Given this, maybe a good first pass at defining a coroutine goes like this:
- A coroutine is a thing (e.g. block of code) that does stuff.
Well, as tempting as this is, it maybe isn't the best way to think about coroutines! In fact, here's a better definition:
A coroutine is a thing that needs to be done.
In other words, a coroutine is a task, rather than the act of doing a task. This distinction comes from Kotlin's own documentation, namely that a coroutine is not bound to any particular thread
. What they're really saying here is there is a difference between the doer (a thread) and the job (the coroutine).
Cooking Stew
Permalink to "Cooking Stew"To clarify the distinction, let's think of a yummy pot of stew. To make that stew, perhaps we needed to follow some steps in a recipe:
- Cut some carrots
- Boil potatoes for several minutes
- Brown some mushrooms
These steps are tasks needed to cook our stew. It's the cooks who actually perform these tasks, and there could be one cook, two cooks, or even a dozen cooks coordinating who does what.
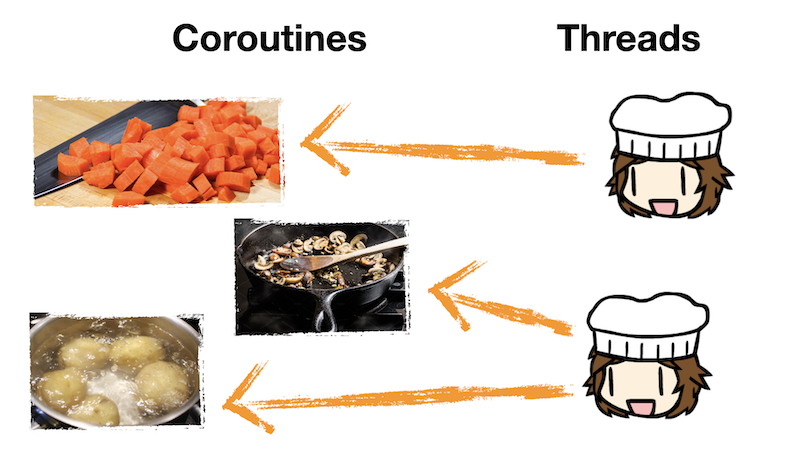
As such, the recipe steps are coroutines, things that need to happen, and the cooks are threads, the things actually executing the code. There is not necessarily a one-to-one correspondence between coroutines and threads.
- One thread could be juggling between multiple coroutines
- One coroutine could, over time, be run by different threads
Parallelism and Concurrency
Permalink to "Parallelism and Concurrency"Another way to think about coroutines is to consider the difference between parallelism and concurrency. Turns out, these concepts are different in one fundamental way: whether tasks are trully happening simultaneously.
- Parallelism is when two tasks truly happen at the same time, and requires more than one worker
- Concurrency is when tasks can be interweaved, in case elements of each task requires waiting
Back to the analogy of cooking stew, let's say you need to cut carrots and brown the mushrooms. If you have two cooks, then one cook can cut the carrots while the other browns the mushrooms, allowing both tasks to complete more quickly than if one cook had to do one task and then the other. This is an example of parallelism.
Meanwhile, consider boiling potatoes while cutting the carrots. Boiling potatoes requires a lot of waiting; instead of waiting all that time, it is more productive to cut the carrots while the potatoes boil, and then eventually come back to the potatoes when it is ready. Only one cook is needed here: they suspend the task of boiling potatoes and in the meantime cut some carrots. This is an example of concurrency.
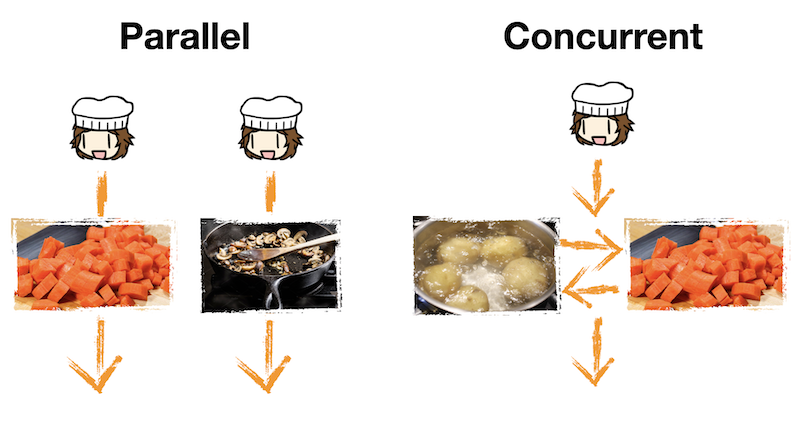
So, coroutines are just ways to break down a big task into different tasks that can be performed concurrently, in parallel, or perhaps both. It is a design philosophy rather than an implementation.
What is Scope?
Permalink to "What is Scope?"All right, going back to the initial hello-world example, if we want a program that actually launches the coroutine, then we need it somewhere in our main function:
fun main() {
launch {
delay(1000L)
println("World!")
}
}
However, if you write this code as-is, the compiler will complain about launch being an unresolved reference (even if imported). You might additionally get a hint that launch requires something called CoroutineScope as a receiver. In other words, launch (and many other coroutine functions) cannot be called by itself; it must be within a coroutine scope first.
At least for our toy example, there are a couple of ways to immediately get a coroutine scope.
fun main() {
GlobalScope.launch {
delay(1000L)
println("World!")
}
}
fun main(): Unit = runBlocking {
launch {
delay(1000L)
println("World!")
}
}
- In the first example,
GlobalScopeis a coroutine scope, and it theoretically allows a coroutine to be created from anywhere. - In the second example,
runBlockingopens a block within whichlaunchcan be called.runBlockinggives you a context, within which is a coroutine scope.
Interestingly, when you run these examples, only the example with runBlocking writes "World!" to the screen; the GlobalScope example terminates too early!
So, what is the difference between the two, what does this have to do with "scope", and how does understanding that difference help write coroutine code?
To answer all of those questions, we're gonna need to dive into the foundations of Kotlin's coroutines...
Structured Concurrency
Permalink to "Structured Concurrency"Kotlin's official documentation has a couple-paragraph section dedicated to something called structured concurrency. As it turns out, Kotlin's implementation of coroutines uses structured concurrency as a core paradigm. For me, understanding this turned out to be the key to understanding coroutine scopes and therefore how to actually structure my code, so I'm gonna spend more than just a couple paragraphs talking about it!
Recalling from earlier, concurrency is when we write tasks that can be interwoven in execution, kind of like boiling potatoes and cutting carrots. To understand the "structured" half, it helps to see what UNstructured code looks like first. For that, here's an example of a rather simple program:
01: Input a sorted list of numbers -> LIST
02: Input a number -> NUM
03: Let I be LIST.length / 2
04: Compare NUM with LIST[I]
If greater, Go to 05
If less, Go to 07
If equal, Go to 09
05: Subtract ? from I
06: Go to 04
07: Add ? to I
08: Go to 04
09: Print “Found!”
One of the things that stands out about this program is its use of goto statements. Some goto statements are used for branching into different parts of the code, and some are used for going backwards and redoing previous code. To help understand what's happening, maybe we could draw some arrows for our eyes to follow.

Even for a program as small as this, the overlapping arrows make it look rather intimidating! Now, imagine a much larger program with hundreds, nay thousands, of lines of code using goto statements in a similar way. If we try to draw all the arrows for that, what does it end up looking like?

Turns out, this is where the term "spaghetti code" originally comes from! When a code's flow is controlled primarily by goto statements, it becomes nearly impossible to follow and difficult to change. Like spaghetti, every noodle of code drags other pieces with it.
Unstructured Programming
Permalink to "Unstructured Programming"Why is goto so painful compared to what we do now? What is it we do now anyway?
Interestingly, one of the principal reasons goto hurts is because it's a one-way jump. To illustrate, let's say I have a recipe book with an entry for stew:
- Cut the carrots
- Boil the potatoes. See page 24 for "How to boil potatoes the right way".
- Brown the mushrooms
- ...and so on
Zooming in on Step 2, we know we need to boil the potatoes, but it appears that boiling potatoes has its own set of instructions we could follow. If you're following the recipe, the natural thing to do here would be to go to page 24 and see how to boil potatoes the right way, and once you've got that going to return to this page and resume at step 3. You wouldn't go to page 24 and just stop there.
In other words, Step 2 above is a two-way jump. First you jump to page 24, and when you are done instinctively jump back to Step 3. And the most interesting thing about this is that's the natural way to follow these instructions; you'd jump back to the stew recipe even if I didn't tell you to.
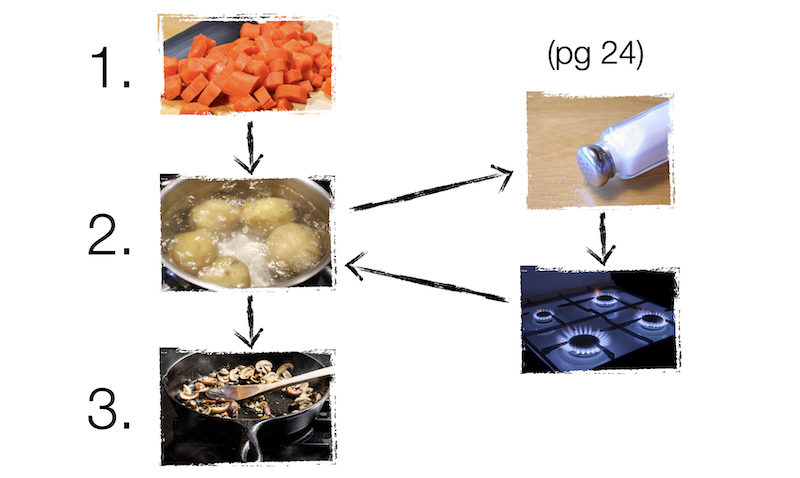
The two-way jump happens to be incredibly useful for understanding recipes because it means if you already know how to boil the potatoes the right way (maybe you've done it before), then you don't need to jump to page 24 to understand the overall recipe. You can create an abstraction: to understand generally how to make stew, you don't need to know the details of boiling the potatoes.
Unfortunately for goto, this isn't true: goto is a one-way jump, meaning it will take you to a different part of the code, but there's no guarantee it will take you back. And because of this simple fact, abstractions become broken.
Here's a practical code illustration (affectionately in TI-BASIC):
:X+(Ans=34)-(Ans=25)→X
:Goto A
:Lbl B
:Y+(Ans=26)-(Ans=24)→Y
Here, perhaps at Lbl A is some code for detecting a key press from the user. Therefore, we need to Goto A to execute that code. We provide a Lbl B for the code to come back to when it is done, but because Goto is inherently one-way, I can't know if it will jump back to Lbl B without looking at the code at Lbl A first.
In order to know what this code will do, I absolutely have to know what's happening at Lbl A. And if my code is constructed entirely of goto statements, that's why it becomes a ball of spaghetti: the only way to know how the program will behave is to know the entire codebase at once.
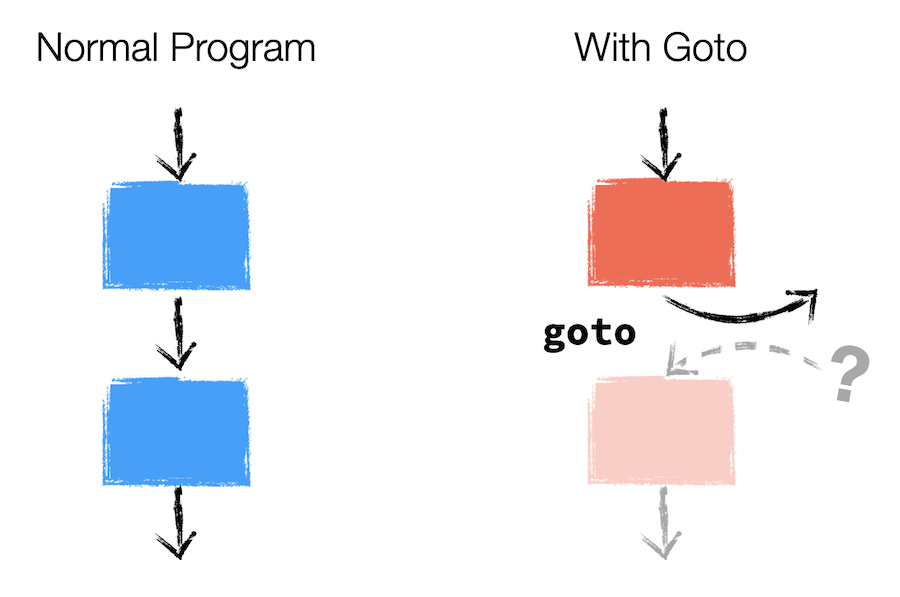
And this is why structured programming was proposed.
Structured Programming
Permalink to "Structured Programming"As the name implies, structured programming utilizes structure to make it possible to understand code in smaller, hierarchical chunks. And actually, you probably rarely ever hear the term "structured programming" nowadays because, well lemme show you:
01: Input a sorted list of numbers -> LIST
02: Input a number -> NUM
03: Let I be LIST.length / 2
04: Compare NUM with LIST[I]
If greater, Go to 05
If less, Go to 07
If equal, Go to 09
05: Subtract ? from I
06: Go to 04
07: Add ? to I
08: Go to 04
09: Print “Found!”
fun search(list, num) {
var i = list.size / 2
while(num != list[i]) {
if(num > list[i])
i -= ?
else
i += ?
}
print("Found!")
}
It turns out structured programming is just regular code nowadays! These two pieces of code are functionally equivalent, except one uses goto and the other uses very familiar control structures: conditions, loops, and functions.
Just like with goto, we can create diagrams for each of the important control structures.
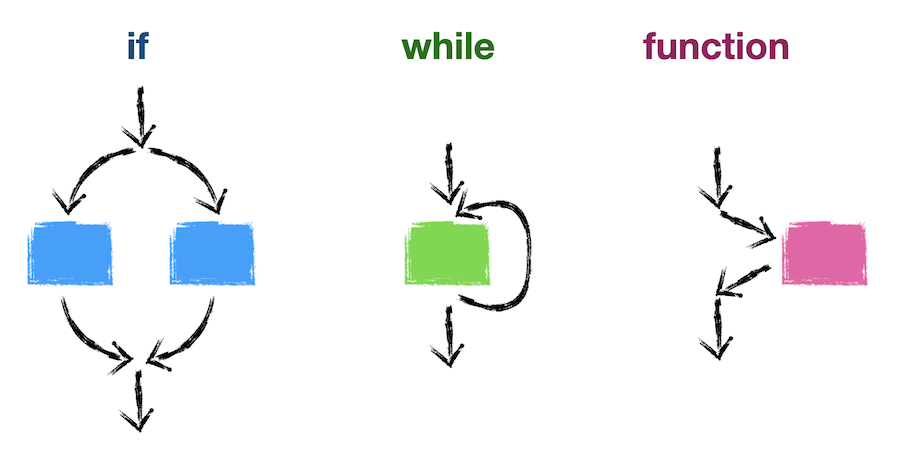
As we can see, they each do something slightly different. However, the key insight is what they have in common: for each of the major control structures, there's one arrow coming in the top and one arrow exiting the bottom! Each structure can be thought of as an opaque box with exactly one way in and one way out.
This property sounds a lot like a two-way jump, and that enables us to create abstractions for our code. No matter how complex the program is, it can always be decomposed into a series of opaque boxes going from top to bottom, meaning:
- The program be understood purely sequentially, like a recipe
- Each opaque box can be understood in a vacuum, where we only need to understand the details if we want to
Structured programming is now the standard, and goto put by the wayside, so much so that goto isn't even an available feature in most languages anymore.
Except! Actually, goto is available. It just has a different form...
Unstructured Concurrency
Permalink to "Unstructured Concurrency"Let's get back to concurrency. This time, we're going to focus on one of our Kotlin examples, in particular the one using GlobalScope.
fun main() {
GlobalScope.launch {
delay(1000L)
println("World!")
}
}
If you run this program, it turns out it actually completes too quickly for "World!" to get printed. It does not wait the one second needed to execute the print. So what's going on?
Well, GlobalScope.launch creates a coroutine which will be picked up and executed by a thread in a default pool. Meanwhile, the main thread will continue executing, which once it hits the end of the program will terminate everything, including the thread currently running our coroutine. Hence, the print never happens.
That may seem like a quirk, but it has dangerous implications. Consider the following example:
fun main() {
snarkyPrintLn("Hello world!")
Thread.sleep(2500L)
snarkyPrintLn("Doing some work...")
Thread.sleep(7500L)
snarkyPrintLn("All done.")
}
Looks simple enough. It's gonna print a few lines after some delays, right?
But when you run this program, actually it outputs the following!
Hello world!
Doing some work...
Lol, this program sucks!
Lol, this program sucks!
All done.
Where did those snarky lines come from (and why are they so rude)?
Well, it turns out the definition of snarkyPrintLn() spawns a coroutine in the global scope:
fun snarkyPrintLn(str: String) {
println(str)
GlobalScope.launch {
delay(5000L)
println("Lol, this program sucks!")
}
}
That coroutine waits a while before sneakily printing the snarky statement. In other words, even after we thought the function was finished in our code, it actually continued to do things in the background. In the toy example above, that was fairly harmless, but this issue could get very hairy and unpredictable as soon as the global coroutine does anything more than print a line!
In the example, to understand the program we needed to understand that snarkyPrintLn() spawned a coroutine, because there was no guarantee that it was actually done doing things after returning. That sounds like a familar problem.
As it turns out, the main issue here is the GlobalScope.launch. The part of the code that kicks off that coroutine has no way of knowing, inherently, when or whether the coroutine is finished. If that sounds like goto's one-way jump, that's because it is, with the only difference being that execution continues concurrent with the coroutine.
You could picture it kind of like this:
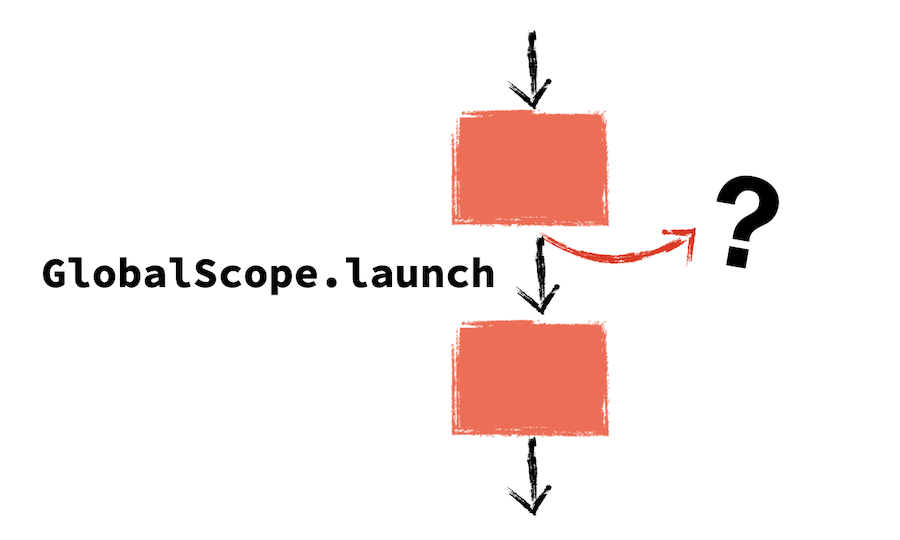
In Kotlin, GlobalScope.launch is the concurrent equivalent of goto! And just like goto, it can undermine the power of our abstractions, like in the above where we couldn't know that snarkyPrintLn() continued executing code after we thought it was done.
It turns out that unlike for structured programming, unstructured concurrency has been the norm in modern software for a long time. Many languages offer an equivalent to GlobalScope.launch capable of spawning an arbitrary concurrent or parallel process:
- C++ lets you construct threads
- Java lets you start threads
- Javascript lets you create promises
So if that's what unstructured concurrency looks like, how do we add some structure?
Back to Structured Concurrency
Permalink to "Back to Structured Concurrency"Let's recall what about structured programming made it "structured":
Each control structure can be thought of as an opaque box with exactly one way in and one way out.
With GlobalScope.launch, we end up in a situation where a coroutine is created with no guarantee about when it completes, effectively meaning an extra arrow leaves the box. If instead we force the main arrow to wait until the coroutine finishes, then we end up with a model that looks like this:
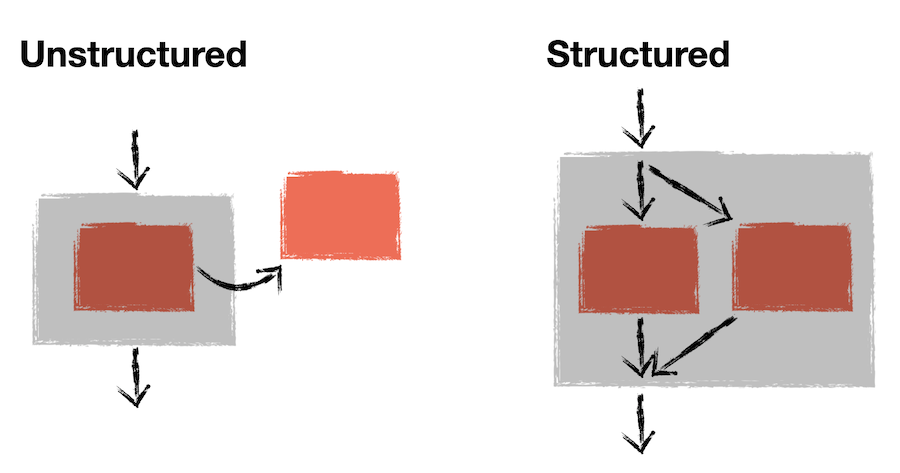
And if you have multiple coroutines:
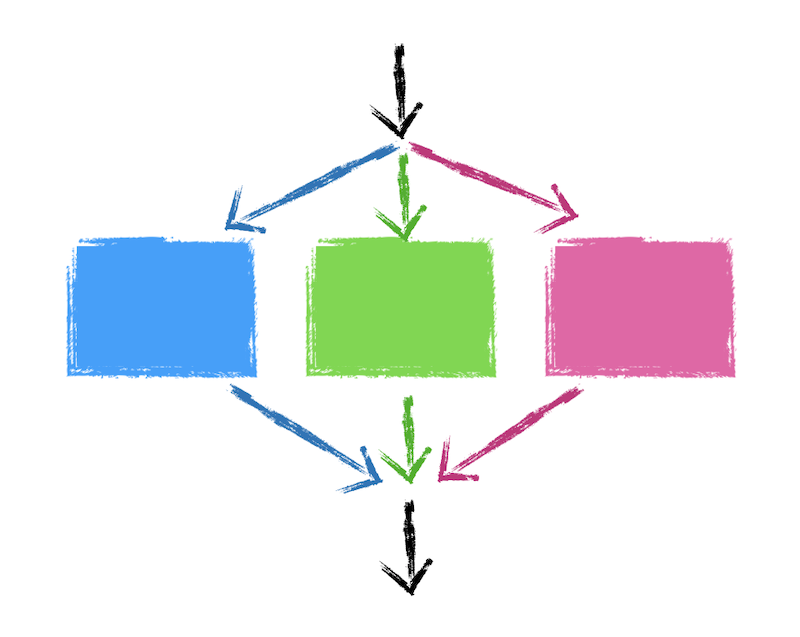
All coroutines created within a context must complete before the program moves on. That's the core essence of structured concurrency.
It turns out this one principle enforces a hierarchical structure in coroutines. If a coroutine needs to create sub-coroutines for itself, that's completely fine. Just like how you can nest if statements together and understand how that branches, coroutines can be nested as well. The top-most coroutines depend not just on their children completing, but their children's children as well.
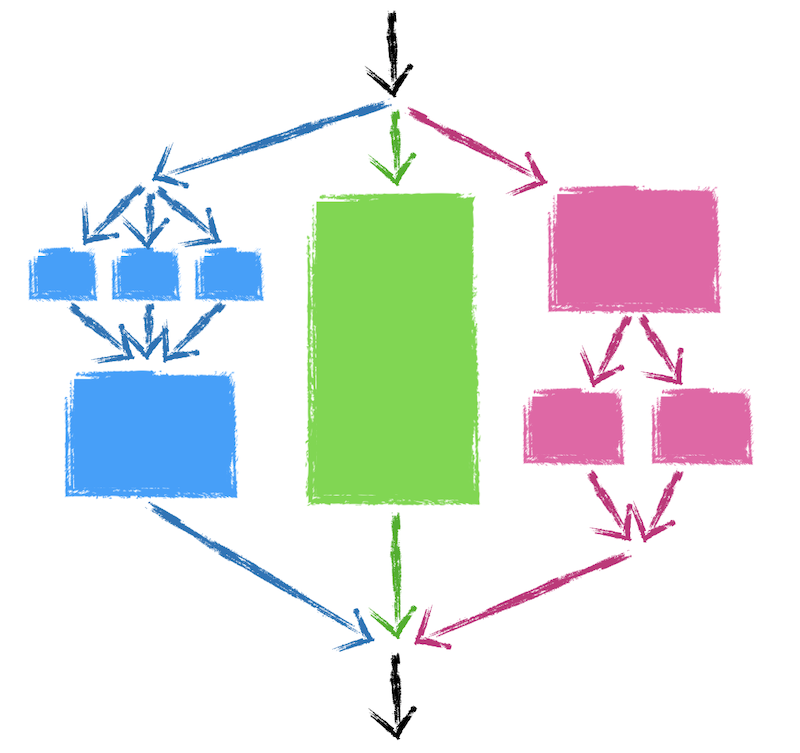
Finally, Understanding Scope
Permalink to "Finally, Understanding Scope"Knowing that structured concurrency is all about implementing the two-way jump for coroutines, we can now understand what a "coroutine scope" is in Kotlin.
Scope defines the lifetime and relationship of its child coroutines.
A coroutine respresents a task can be divided into child coroutines, defining the relationship. The parent coroutine is only finished whenever all of its children are finished as well, defining the lifetime.
If we revisit the hello-world example, this time without GlobalScope.launch, we find ourselves using something different:
fun main(): Unit = runBlocking {
launch {
delay(1000L)
println("World!")
}
println("Hello")
}
runBlocking opens up a coroutine scope within which we can launch new coroutines. The difference is that rather than opening a parentless coroutine, runBlocking will block the main thread until the scope within is complete, and remember: the scope is only finished once all the coroutines within are complete! Therefore, this program actually does print "World!" after a second.
And revisiting the snarky program...
If snarkyPrintLn() is to be rewritten without GlobalScope, then it actually requires a scope to come from somewhere. We can pass it as a parameter:
fun CoroutineScope.snarkyPrintLn(str: String) {
println(str)
launch {
delay(5000L)
println("Lol, this program sucks!")
}
}
Interestingly, requiring a CoroutineScope as a parameter serves as a hint to the developer that the implementation of the function utilizes coroutines in some way. But since we are using structured concurrency, we do not need to know exactly how it utilizes coroutines to do what we want.
Looking now at our program without GlobalScope:
fun main() = runBlocking {
snarkyPrintLn("Hello world!")
delay(2500L)
snarkyPrintLn("Doing some work...")
delay(7500L)
snarkyPrintLn("All done.")
}
We can decide whether we want the prints to happen concurrently or if they truly need to act sequentially. For instance, if we need to know that snarkyPrintLn() is fully complete before continuing our code, we can wrap it in a coroutineScope delimiting its lifetime.
fun main() = runBlocking {
coroutineScope { snarkyPrintLn("Hello world!") }
delay(2500L)
coroutineScope { snarkyPrintLn("Doing some work...") }
delay(7500L)
coroutineScope { snarkyPrintLn("All done.") }
}
Recalling our rule that the scope only completes once all its child coroutines complete, creating a scope around snarkyPrintLn() guarantees our code won't continue until it is done. As a result, the snarky statements get printed in order rather than some point later than possibly expected.
What if a Coroutine Ends Prematurely?
Permalink to "What if a Coroutine Ends Prematurely?"Knowing that the lifetime of a parent coroutine is dependent on its children, we can start thinking about what happens when a coroutine is cancelled or has an error.
In order to maintain structured concurrency, there are essentially three big rules:
- Building a coroutine within a scope makes it a child of that scope
- Cancellation of a parent cancels all the children
- Catastrophic failure of a child cancels its parent and siblings
Scope delimits the lifetime of coroutines. That means coroutines created in that scope should only ever live within that scope and not leak out.
For cancellation, cancelling the parent must cancel all its children to ensure their work does not leak into other scopes.
Errors, meanwhile, bubble up the tree of scopes until they run into an error handler. If the error bubbles out of a coroutine scope, then in order for potentially parallel processes to not leak of the scope, they must be cancelled as well. This is why a catastrophic failure cancels the parent scope and its children.
In a Nutshell
Permalink to "In a Nutshell"Kotlin utilizes structured concurrency as a paradigm for managing coroutines. Coroutines represent tasks in code that need to happen and operate with hierarchical scopes which determine the lifetime and relationship of the coroutiens within.
Utilizing Kotlin's mechanisms for coroutine scope allows you to write concurrent code with specific guarantees that can lead to less side effects and therefore solid abstractions.
Even though Kotlin coroutines were foreign to me at first, I've since fallen in love with the paradigm, and find myself missing structured concurrency in other languages.
That said, Kotlin's support of coroutines goes very deep, into other sorts of things like channels and flows. Understanding structured concurrency is, in my opinion, the first step to understanding everything else. So, hopefully this article has been helpful in taking that step!
References
Permalink to "References"Here are some very great references that helped me understand structured concurrency.