Meet Kafka
- What if Carol lives far away?
- What if Pat has many kinds of messages she wants to send?

- What if Carol only wants to listen to certain kinds of messages?
- Carol wants to save time by processing LOTS of messages in parallel.

- What if Carol only wants to listen to certain kinds of messages?
- Carol wants to save time by processing LOTS of messages in parallel.
- Both Carol AND Cathy want to read the same messages.
- Mediate messages between producers and consumers.
- Allow users to choose what topics matter to them.
- Facilitate scalability through parallel processing.
- Continue service even in the face of failures and downtime.
- Support multiple ways of consuming data.

- Mediate messages between producers and consumers.
- Allow users to choose what topics matter to them.
- Facilitate scalability through parallel processing.
- Continue service even in the face of failures and downtime.
- Support multiple ways of consuming data.
- Guarantee messages from partitions are processed in proper order.
- Stream data real-time from producers to consumers.
- Allow for data to be reprocessed if needed.
By the way: This article is an adaptation from a presentation I gave while working on a data engineering project.
If you're working in a system that deals in either data or events, then you might have heard of this thing called Kafka.
There are already a myriad of articles describing Kafka, how it works, and how to use it. They do a splendid job explaining at both an abstract and technical level stuff you'd want to know about Kafka, so instead I'm going to take a more narrative approach.
My goal is to create a mental model for why Kafka is designed the way it is, with Topics and Paritions and Consumer Groups and whatnot, because understanding the why is often more important than understanding the how when it comes to designing system architecture.
Messages
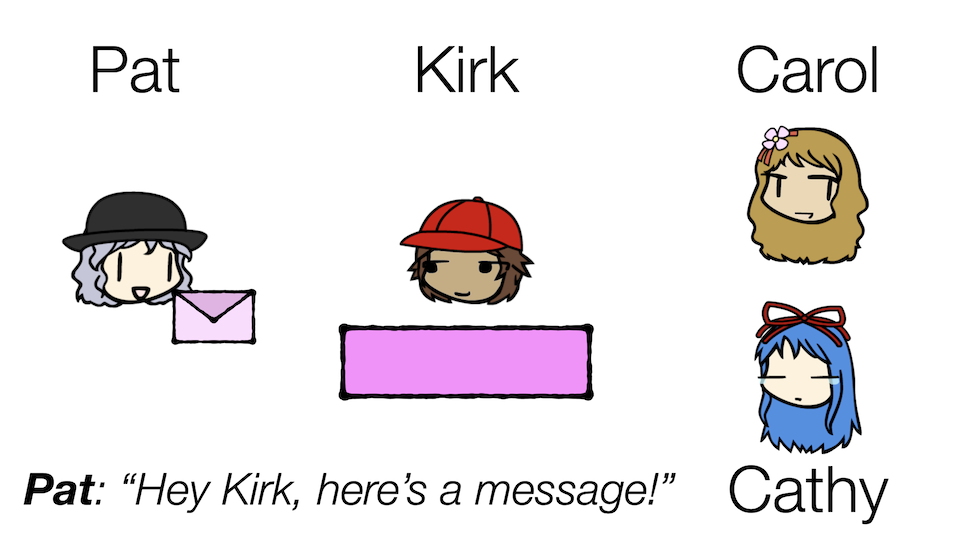
To start, meet Pat and Carol!
Pat and Carol are friends who often exchange messages with each other. Let's say Pat has a message that she wants Carol to read. How can she get that message to Carol?
Well, one thing she might try is simply walk over to Carol and hand over the message in person.
But unfortunately, that will not work! You see, Pat has a pressing problem.
Pat cannot just walk over to Carol because she lives too far away. Instead, maybe she hands her message to a mediator of some sort, someone who would be responsible for ensuring Carol receives the message.
So, meet Kirk, the mail guy! His main job is to deliver messages between different people, kind of like so:
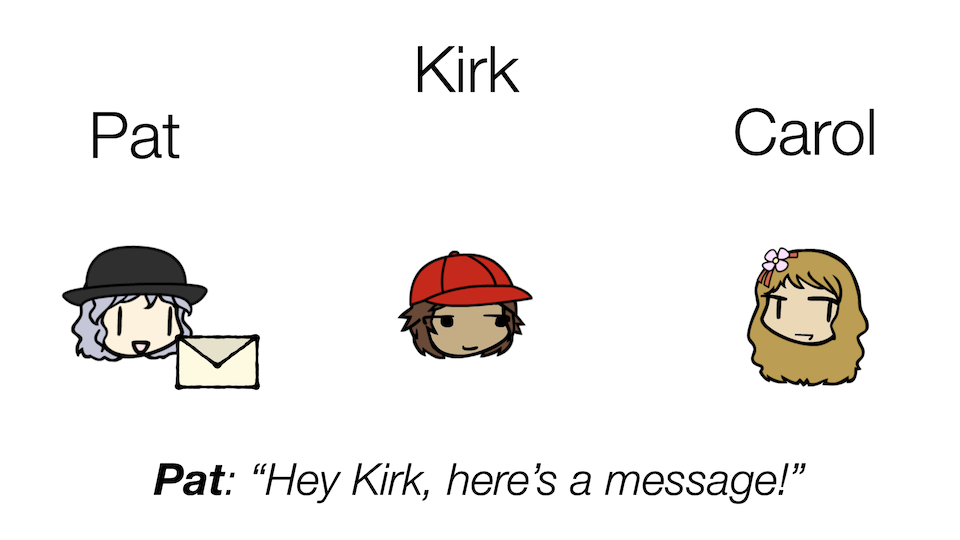



Turns out, this is a useful way of thinking about what Kafka can do! In this analogy:
- Pat is a producer, a service that creates messages or events
- Carol is a consumer, a service that processes messages or events generated elsewhere in a system
- Kirk is Kafka, facilitating the flow of events from producers to consumers
As we continue the analogy, we can learn a lot about Kafka by enumerating Kirk's goals.
What is Kafka?
Before we go deeper into Analogyland, let's take a quick step back and consider what Kafka really is technologically.
Funnily enough, depending on what you read, you may rather diverse definitions. At the time I wrote this:
- Wikipedia calls Kafka a
software bus using stream processing
- AWS says Kafka is a
distributed data store
for streaming in real-time - And Apache (the creators) calls it an
event streaming platform
The key words here are event, store, and stream. In a software system, when an event happens, Kafka stores the event and streams it to consumers that care about that event.
Keep event, store, and stream in mind as we explore Kafka deeper. Those three key words will help illustrate why Kafka works the way it does!
Topics
Ok, let's get back to Pat and Carol! Let's say Pat now has two different kinds of messages. Casual messages are for her friends to read, and Business messages are for her coworkers.
Meanwhile, Carol is just Pat's friend, not a coworker; therefore, Carol only cares about the casual messages.
And to make this more complicated, Pat's messages may not be addressed to any particular person. Rather, her casual messages could be read by any of her friends, and likewise the business messages could be read by any of her coworkers.
This seems to make Kirk's job as the mediator a bit more complicated! If Kirk is going to deliver casual messages to Pat's friends, does this mean Kirk now has to know who Pat's friends are?
Or, maybe that means Pat has to now address each of her letters to the individuals meant to receive them. However, while she may know who all her friends are, maybe she does not know who all her coworkers are! After all, Pat works for a big company who gets new employees quite often.
- Kirk does not want to force himself to know who all of Pat's friends are.
- Pat does not want to force herself to know who all her coworkers are.
That's fine! Kirk has a clever idea.
He can set up mailboxes for different kinds of messages! Casual messages will go into the Casual mailbox, and Business messages will go into the Business mailbox. Carol can then subscribe to only the Casual mailbox and therefore only receive casual messages.

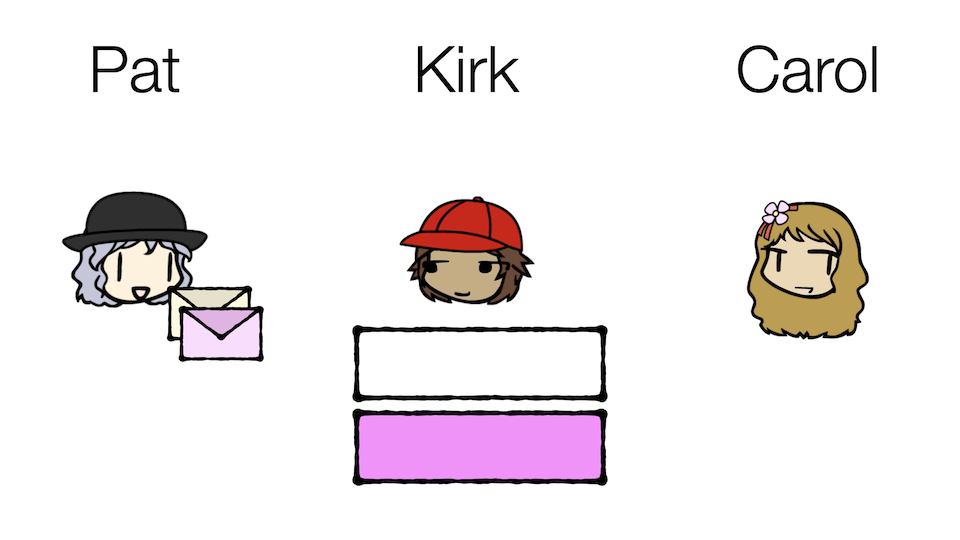
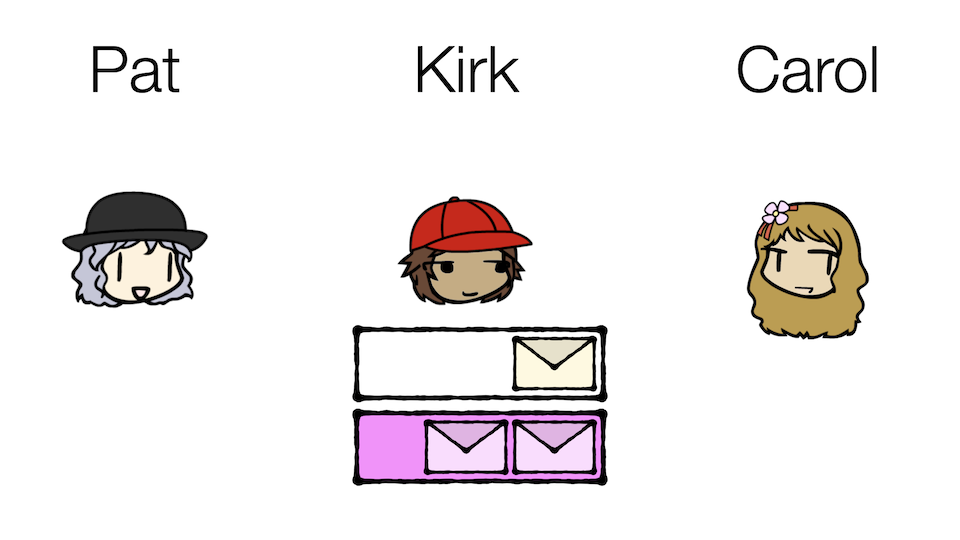
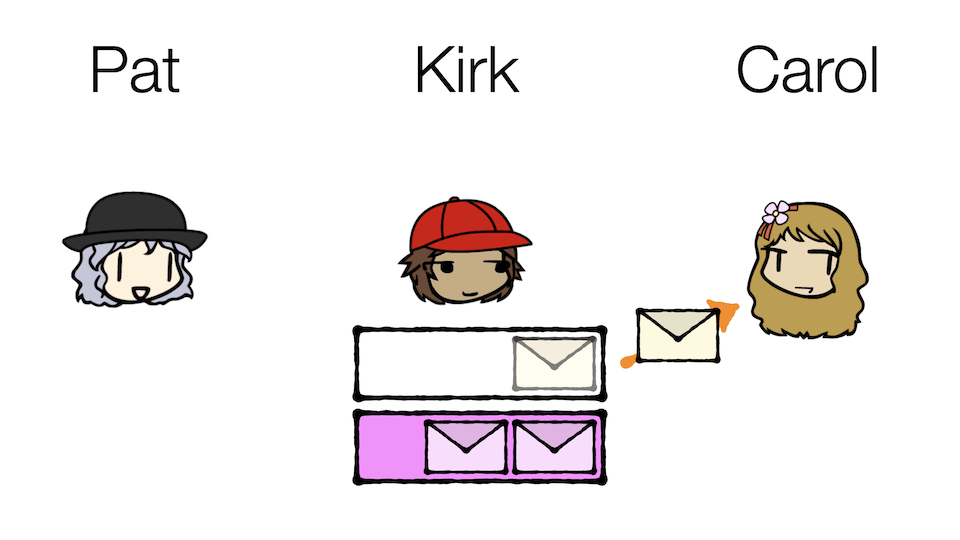
Notice what this mailbox strategy accomplishes:
- Kirk does not need to know who is consuming the messages, which is quite a bit simpler for him.
- Pat only needs to publish her messages to the correct mailboxes and doesn't have to worry about every individual person consuming her messages.
- In fact, Carol does not technically even need to know who originally published the message! Maybe Pat, Carol, and the rest of their friends can all share the same Casual box amongst themselves.
A key insight is that messages are stored in the topics for a while so that different consumers can read the same message. Later when we talk about consumer groups, we will explore this storage concept further.
In Kafka's world, these "mailboxes" are called topics. Each topic is essentially an event stream; one topic could be used for customer purchases, a different topic for account creations, and so forth.
Rather than talk to the producers directly, consumers subscribe to topics in order to process the events within them. A big benefit of this model is that it facilitates the decoupling of the producers and consumers. Since the communication happens via Kafka, the mediator, producers and consumers can evolve independently, and new producers and consumers can be introduced to the system without requiring direct modification of any other system.
Partitions
Ok, time to create a pretty weird problem for Kirk. Let's say Carol has somehow learned how to clone herself...
Team Carol wants to save time by reading multiple messages simultaneously, rather than always one at a time. This poses an interesting dilemma for Kirk and his topic pattern. The topics are designed so that multiple consumers can read the same messages from the same topics. In other words, if Pat publishes a message to the Casual topic, then all of her friends can read that message.
That's a problem if there are multiple Carols, because it means each individual Carol will read the same messages. That defeats the purpose of Carol cloning herself: the goal was to save time by collectively reading all the messages rather than each individual Carol reading each message.
To further illustrate, imagine there are three members on Team Carol. Now, let's say Pat publishes three messages to Kirk. Ideally, each member of Team Carol will read exactly one message; by doing so, they will have collectively read all the messages in just one-third the time. Pretty efficient!
Unfortunately, unless something about the topic model changes, what will actually happen is each Carol will read all three messages. That's a lot of wasted time.
This might sound like Carol's own problem, but actually there's a clever trick Kirk can do to help!
Kirk will actually divide the topic into mini-mailboxes. Each member of Team Carol can then be put in charge of one or more of the mini-mailboxes. When messages enter the topic, they can be distributed into the mini-mailboxes so that the work is effectively divided as evenly as possible across the different consumers.
As you might have guessed, these "mini-mailboxes" are what Kafka calls partitions.
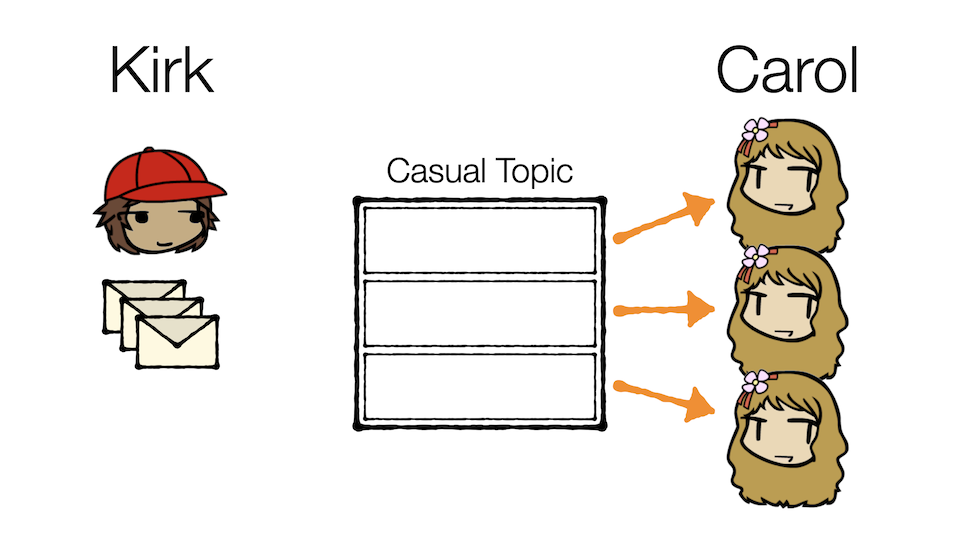
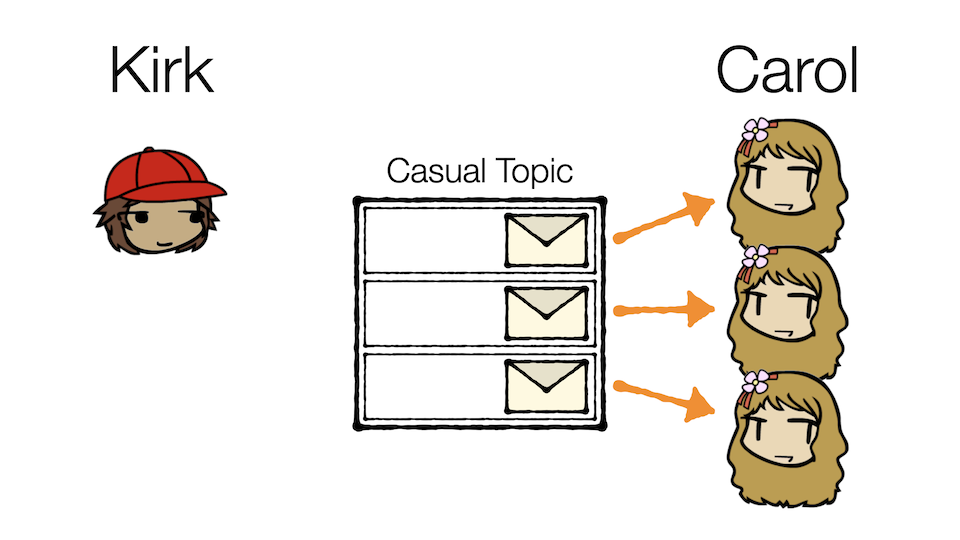
So in this illustration, three events enter the Casual Topic, but are divided evenly across three partitions. Since each Carol is responsible for one partition, each message will be read exactly once, and in parallel.
Partitions are one of Kafka's main mechanisms for facilitating parallel processing, which can dramatically improve the performance of high-throughput architectures.
Are Partitions Necessary?
When I was first reading about Kafka partitions, it felt like a somewhat convulted and perplexing solution to the parallel processing problem. Why doesn't Kafka just stuff all the messages into the topic and distribute the messages evenly to the consumers?
Recall one of our key words: each envelope is an event. Events are ordered, and that order matters. If I make a purchase and then cancel my purchase, it doesn't make sense for the system to first process the cancellation and then process the purchase; it would be backwards!
Looking at the illustration above, we have two envelopes:
- The blue envelope was published first
- The yellow envelope was published second
It may seem like the blue envelope will in fact get delivered to one of the Carol's first. Unfortunately, in software that can't be guaranteed. There are a number of reasons why the blue envelope might get delayed in transit, and if it gets delayed at all, there's a chance the yellow event will get delivered before blue.
The fundamental insight is this:
To guarantee ordering, a partition can only serve exactly one consumer.
As soon as a partion serves more than one consumer, there's a chance messages can get out of order. Therefore, Kafka allows for multiple partions so that there can be multiple consumers, at most one consumer per partion.
Some key points from this:
- There cannot be more consumers than partitions, meaning that the number of partitions should be chosen carefully to facilitate the desired parallelism. Do note that there can be more partitions than consumers though, since a consumer can pull from multiple partitions without breaking ordering constraints.
- Order is only guaranteed within a partion, and not across partitions! This means it is important how the events are partitioned as well. For example, any updates I make to an order I placed should go into one partition, but a different person's order updates can go to a different partition since our orders are independent of each other.
Replicas
Let's say Kirk decides to clone himself using Carol's machine so that each Kirk can be put in charge of one partition.
Now that we have Team Kirk and Team Carol, work can truly be done in parallel! But there's a potential problem here. What would happen if one of the Kirk's, say the bottommost, gets sick and can no longer do his job? He was in charge of the bottom blue partition, which was being read by one of the members of Team Carol. If he is no longer managing that partition, then what happens to all the messages going to that partition?
As someone who has worked in various products, I can tell you that servers just stop all the time, sometimes for seemingly no reason. Fault tolerance is one of our key concerns as software engineers; even in the face of downtime, things should either continue working or recover quickly and safely.
Well, nobody said a partition must be handled by only one Kirk. What if instead each partition could be owned by more than one Kirk? One Kirk would have the main responsibility over that partition, but another could serve as a backup in the worst case scenario!
Here, the blue (bottommost) partition has a replica belonging to the middle Kirk. Replicas are Kafka's solution to resiliency and fault tolerance; even if one Kafka instance shuts down, other instances can take over the data streams without affecting the producers or consumers. They serve as backups to partitions, distributed across different Kafka servers (called brokers).
Consumer Groups
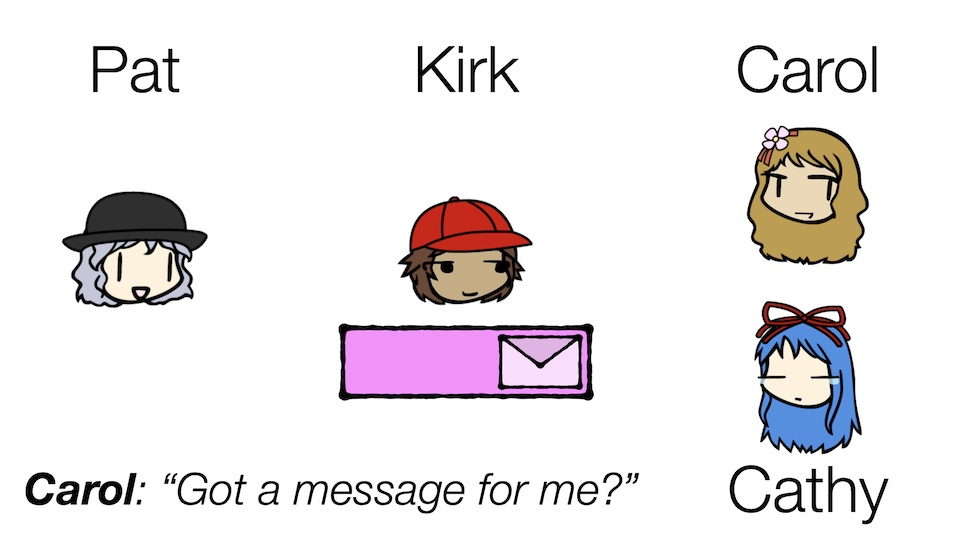
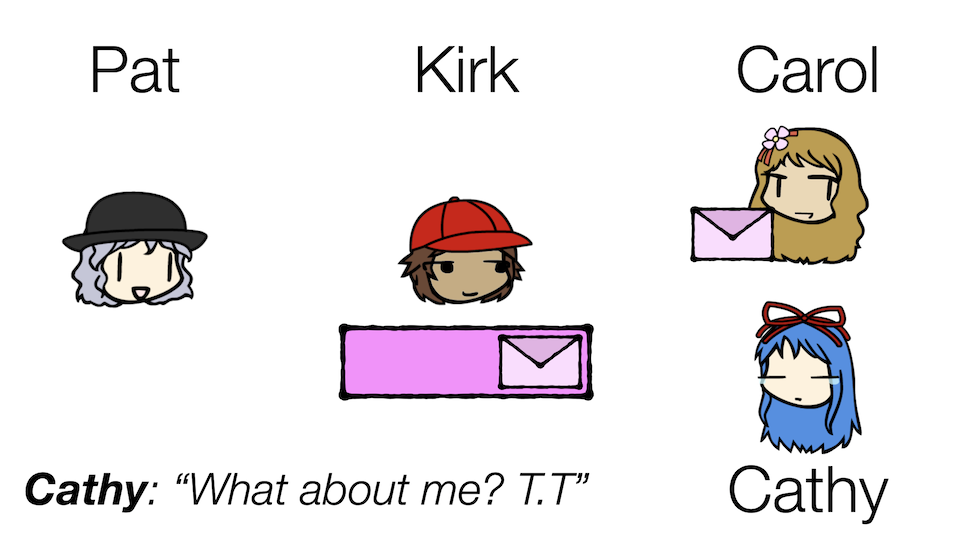
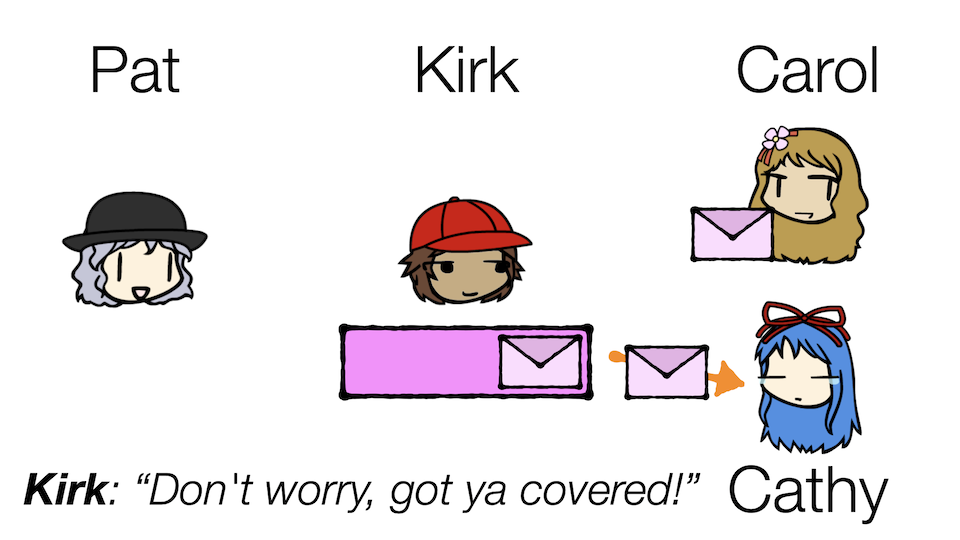
Well, looks like Pat just got a new coworker! Meet Cathy.
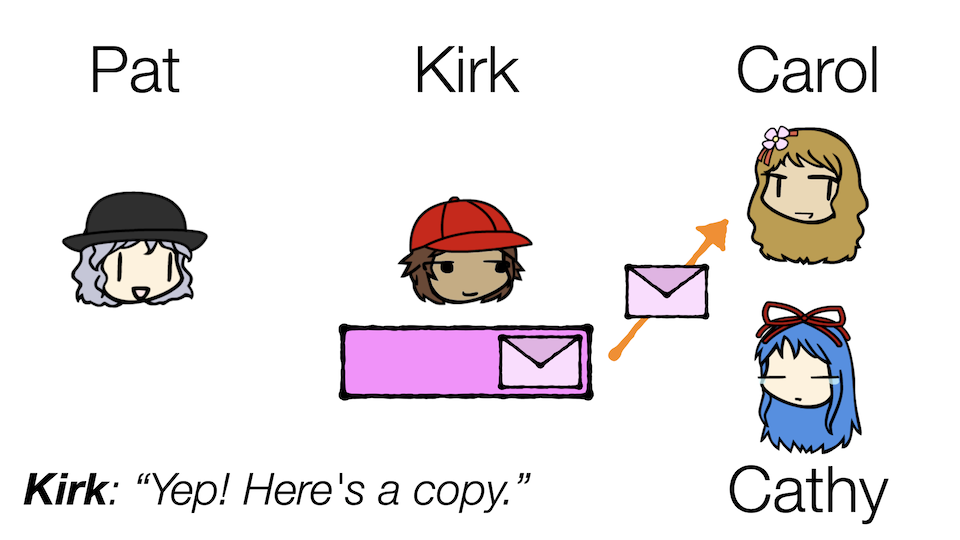
Kirk now needs to ensure that both Carol and Cathy can read the same message. Note that this is different from before where he had to serve multiple Carols. In the Team Carol scenario, collectively the Carols want to read all the messages, and yet no two Carols should read the same message. With this new situation, however, both Carol and Cathy want to read the same messages, because they might want to do different things with them.
Let's recall one of our key words: store. It turns out, partitions actually persistently store events in them, allowing for events to be processed multiple times by different consumers. Kirk can take advantage of this to serve both Carol and Cathy!
This can be different from traditional messaging systems, wherein a message is removed from the queue once it is processed. In Kafka, messages stay in the partition for a set amount of time.

Events do not need to be stored in Kafka forever; indeed, in the world of big data storing events forever can become expensive! Kafka can be configured to remove messages after a certain amount of time, e.g. 24 hours.
As it turns out, in Kafka terminology, Cathy would be considered a different consumer group from Carol. One consumer group represents a set of instances wanting to read topic data in parallel; other consumer groups, then, represent different sets of instances wanting to read from, potentially, the same topics, but may process the data for a different purpose.
The idea of consumer groups, along with partitions, allows Kafka to support different ways of consuming data.
With consumer groups, Kirk can:
- Distribute messages evenly to different members of a single consumer group
- Broadcast messages to all different consumer groups invested in the topic
- Or a combination of the two approaches above
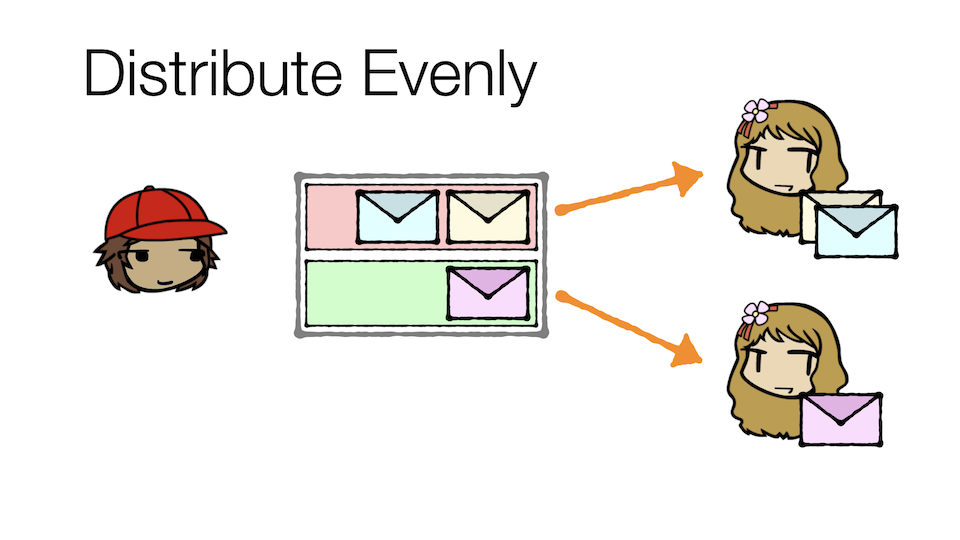
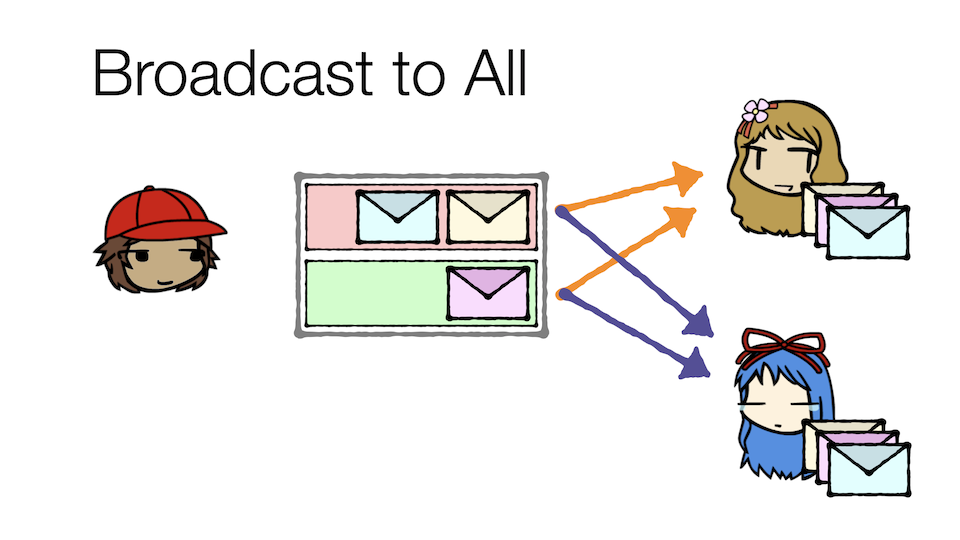
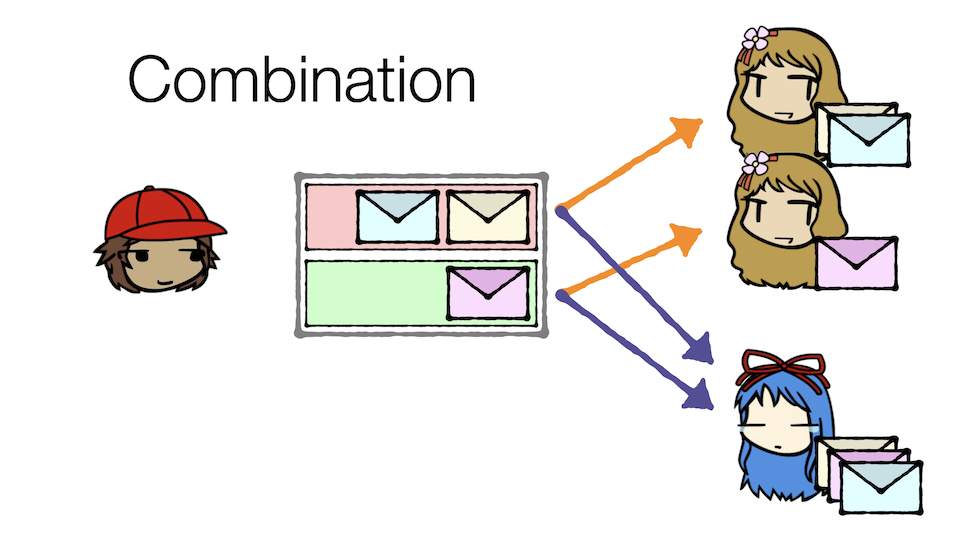
Note that in all the above approaches, each consumer group sees all three messages in the topic. Therefore, both Carol and Cathy each see all three messages, though in Carol's case (because she's a cloner) she may divide the work between herself and other clones.
To Summarize
Remember all of Kirk's goals we've been compiling? Turns out, Kafka has those exact same goals, along with a few others worth mentioning! (surprising, I know)
These goals are why Kafka is designed with topics, partitions, replicas, and consumer groups. Together, these facilities help accomplish the various needs of data engineering and event streaming.
Hopefully this has been helpful in understanding the why behind Kafka's components. Of course, I did not go at all into how, practically, you would do any of this! For that, I recommend looking at some of the resources below to continue your Kafka journey.